Building a Linearizability Checker in Rust
I have been working through the implementation of the Raft consensus algorithm in Rust. Part of doing that properly is being able to test it: you need to throw concurrent histories at your implementation and ask whether they are consistent with what a correct register (or log, or key-value store) is supposed to do. That question has a precise name — linearizability — and answering it algorithmically turns out to be a genuinely interesting problem.
This post walks through what linearizability means, how a checker works, why the naïve approach is too slow to be useful, and what the optimised implementation looks like. The project is a Rust port of porcupine by Anish Athalye. The code is on GitHub and the README has full usage details.
What is linearizability?
The central question is deceptively simple:
Can this interleaved, concurrent execution be explained as some valid sequential execution of the same operations?
More precisely: a concurrent history is linearizable if there exists a total ordering of all operations such that:
- The ordering respects real-time: if operation A completed before operation B started, A must precede B in the ordering.
- Every operation in the ordering satisfies the system’s sequential specification.
The moment at which an operation appears to take effect in the chosen ordering is called its linearization point. It must fall somewhere within the operation’s actual call/return interval.

To make this concrete, consider a single-register service. Client 0 writes 1, client 1 writes 2, clients 2 and 3 read concurrently. Client 2 reads 2, client 3 reads 1. Is this history linearizable?
It is: one valid ordering is write(1), write(2), read→2, read→1 if the reads overlap with the writes. But if both reads happen after both writes complete, then both reads must return the same value — whichever write was last — and returning different values is a violation.
The brute-force algorithm
The algorithm is a depth-first backtracking search. The invariant is: at each step, we have a set of remaining operations and a current model state. We pick an eligible operation, check whether the model accepts it, and if so recurse with that operation removed.
linearizable(remaining, state):
if remaining is empty: return true // base case
for each eligible op in remaining:
(ok, next_state) = model.step(state, op)
if ok:
if linearizable(remaining − {op}, next_state):
return true
return falseEligibility is the key constraint. An operation op is eligible only if
no other remaining operation completed entirely before op started. In
other words: for every other remaining r, r.return_time > op.call_time.
Why does this constraint matter? If some other operation o finished before
op started, then in any valid linearization o must precede op. Trying to
place op first while o is still pending would violate the real-time
ordering requirement. The eligibility check prunes those branches immediately.
In Rust, the core of the brute-force is about 30 lines:
fn linearizable<M: Model>(
ops: &[Operation<M>],
remaining: Bitset,
state: &M::State,
cache: &mut Cache<M>,
) -> bool {
if remaining.is_empty() { return true; }
for i in 0..ops.len() {
if !remaining.is_set(i) { continue; }
if !eligible(ops, &remaining, i) { continue; }
let (accepted, next_state) = M::step(state, &ops[i].op);
if accepted {
let mut next_remaining = remaining.clone();
next_remaining.clear(i);
if linearizable(ops, next_remaining, &next_state, cache) {
return true;
}
}
}
false
}This is correct and reasonably easy to reason about. The problem is the complexity. In the worst case the search tree has O(n!) leaves, and even with the eligibility pruning, realistic histories with a dozen concurrent operations can take minutes.
Why the brute force is too slow — and how to fix it
The cache
The first observation is that the search can reach the same (remaining_set, model_state) pair via many different orderings of earlier operations. For
example, if operations A and B commute (the model produces the same state
regardless of order), then linearizing A then B and linearizing B then A both
land at the same point. Without memoization, the search explores the subtree
from that point twice.
The fix is straightforward: memoize visited (remaining_set, state) pairs.
If the search reaches a pair it has already proven is a dead end, it returns
false immediately.
The remaining set is represented as a bitset — one bit per operation,
packed into u64 words. The cache key is an FNV-1a hash of the bitset mixed
with the state’s SipHash, which maps each distinct (bitset, state) pair to
its own bucket with overwhelming probability. Lookup is O(1).
For complex model states like BTreeMap<String, String> (as in the key-value
model), the key mixing is important: without it, many different states with the
same bitset would collide into the same bucket, forcing expensive equality
scans on every lookup.
The skip-list
The second problem is more subtle. In the brute-force, every recursive call
builds a new Vec<Operation> by filtering out the chosen operation:
let rest: Vec<_> = remaining.iter()
.enumerate()
.filter(|(j, _)| *j != i)
.map(|(_, o)| o.clone())
.collect();For a history of n operations, this is O(n) work per recursive call. With a search tree of depth n, you have O(n²) total allocations just for bookkeeping. For large histories these allocations dominate runtime.
The solution is an index-based doubly-linked list — what the implementation
calls the skip-list. The history is stored as a flat Vec, and “removing” an
operation is a pair of pointer updates: next[prev[i]] = next[i] and
prev[next[i]] = prev[i]. Restoring it on backtrack is the same pair in
reverse. Both operations are O(1) and allocate nothing. The list never grows or
shrinks; only the prev/next index arrays are mutated.
The key invariant that makes restore correct: remove does not clear
prev[i] and next[i]. Those values are preserved, so restore can splice
i back in exactly where it was — no need to remember the neighbours
separately.
Putting it together: the iterative WGL algorithm
With the skip-list in place, the recursion becomes an iterative scan. At each step we look at the first active entry in the list:
- If it is a Call entry, try to lift the corresponding operation. Check the model and the cache; if both accept, remove the call and return entries from the list, push a backtracking frame, and restart the scan from the beginning.
- If it is a Return entry whose Call has not been lifted, every operation that could legally precede it has been tried and failed. Backtrack: pop the last frame, restore the two skip-list entries, and continue scanning from after the restored call.
The “return at the head” condition replaces the explicit eligibility check. An operation’s Call entry appears before its Return entry in the sorted list. If the Return is at the head, the Call was scanned (and rejected) earlier, and no other operation can be placed before this one without violating real-time order. The sorted order enforces eligibility implicitly.
fn check_single<M: Model>(partition: &Partition<M>, kill: &AtomicBool) -> bool {
let n = partition.check_history.len();
let mut lz = Linearizer::<M>::new(partition, compute_info);
let mut cur = lz.front();
while cur < n {
if kill.load(Ordering::Relaxed) { return false; }
match partition.check_history[cur] {
CheckEntry::Call { .. } => {
if let Some(next_state) = lz.try_linearize(cur) {
lz.lift(cur, next_state);
cur = lz.front();
} else {
cur = lz.next_of(cur);
}
}
CheckEntry::Return { .. } => {
match lz.backtrack() {
Some(pos) => cur = lz.next_of(pos),
None => return false,
}
}
}
}
true
}Eight lines in the loop body. Each line has exactly one job. The Linearizer
struct owns all the mutable state (skip-list, model state, bitset, cache,
backtracking stack) and exposes three domain operations: try_linearize, lift,
backtrack. The loop only asks “which candidate next, and should I continue?”
Design decisions worth calling out
type Op instead of separate Input/Output. The model trait uses a
single combined operation type for step. Instead of matching on (input, output) and needing a _ => panic! arm, each Op variant carries exactly
what step needs. The pairing of call inputs with return outputs happens once
in combine (required only when using the event-based API). step itself
becomes a clean exhaustive match.
Model vs EventModel. The check_operations path only requires Model.
The check_events path requires EventModel, which extends Model with
Input, Output, and combine. Models that are only tested via
pre-constructed operation histories need not implement EventModel at all.
Parallel partitions with early termination. Independent partitions are
checked on separate threads using crossbeam::thread::scope. The coordinator
receives results over a bounded channel. The moment any partition returns false
(non-linearizable), the kill flag is set and all other threads exit at their
next iteration. Rayon’s par_iter cannot do this because it collects all
results before returning; the channel-based approach stops as soon as the
answer is known.
Usage
The API surface is small. Define a model, build a history, call one of the check functions:
// Check a history of completed operations.
let ok = porcupine::check_operations(&history);
// With a timeout.
let result = porcupine::check_operations_timeout(&history, Duration::from_secs(10));
// CheckResult::Ok | Illegal | Unknown
// With full diagnostic info (for visualization).
let (result, info) = porcupine::check_operations_info(&history);
porcupine::visualize_path::<MyModel>(&info, Path::new("out.html"))?;The check_events family works identically but takes interleaved Event::Call
/ Event::Return slices instead of completed Operation structs. This is
useful when your test harness records events as they happen rather than
constructing operations after the fact.
For detailed usage — how to implement Model and EventModel, how
partitioning works, how to add annotations to visualizations — see the
README.
Visualization
For any history checked via check_*_info, you can produce an interactive
HTML visualization with a single call. The output is a self-contained file that
runs entirely in the browser.
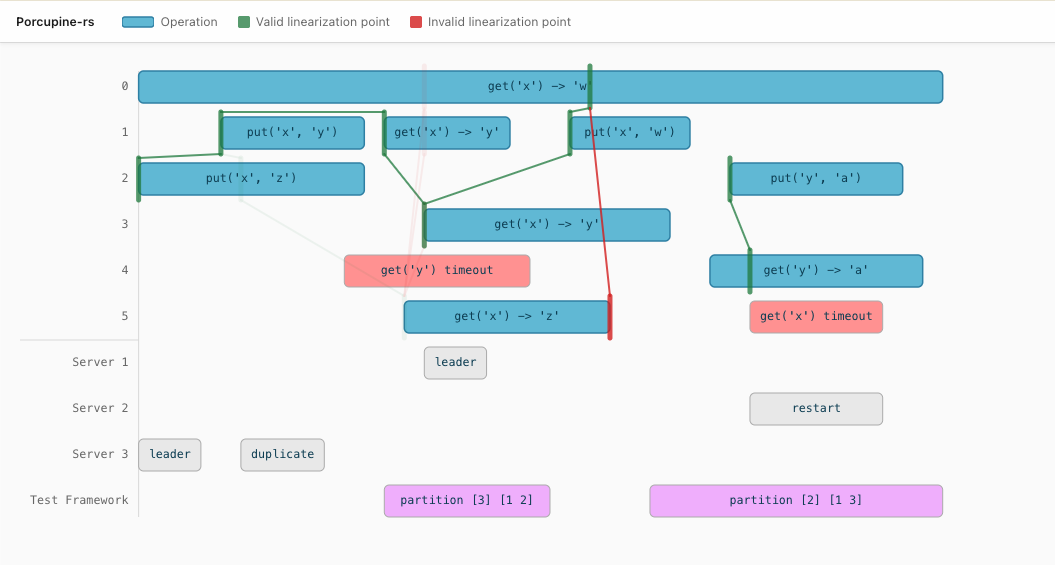
Hovering over an operation bar highlights the most relevant partial linearization and shows a tooltip with the previous and current model state plus the raw timestamps. Clicking pins the selection. A “jump to first error” link in the legend scrolls directly to the leftmost invalid linearization point.
For the tooltips to be informative, implement describe_operation and
describe_state on your model. The defaults fall back to {:?} formatting,
which is readable enough for development but not ideal for sharing results.
Benchmarks: Rust vs Go
The most demanding test case is the key-value store history with 10 clients and no per-key partitioning — a single partition covering all operations, which is the worst case for the search. Running the same history on both implementations:
| Time | Allocated | Allocations | |
|---|---|---|---|
| Go (porcupine) | 24.5 s | 9.1 GB | 540 million |
| Rust | 1.22 s | — | — |
About 20× faster.
The Go allocation figures explain the gap. 540 million allocations at 9.1 GB averages to roughly 17 bytes each — consistent with a linked-list implementation where every node is an independent heap object. Under that allocation pressure the GC runs almost continuously. The wall-clock time of 69 s in the Go test output versus the 24.5 s benchmark figure reflects the rest of the GC cost bleeding into test setup and teardown.
The Rust implementation eliminates most of this in three places:
Skip-list. The entire history lives in a flat Vec; lift and restore are
two index writes each. No heap allocation per operation.
Bitset in-place mutation. try_linearize sets the bit, does the cache
probe, and clears it again before returning. A Vec<u64> clone is taken only
on a genuine cache miss — the rare case. The common case (cache hit, skip this
candidate) allocates nothing.
Cache key mixing. The FNV-1a bitset hash combined with the state’s SipHash
puts each (linearized_set, BTreeMap_state) pair in its own bucket. The
alternative — keying only on the bitset hash — causes bucket collisions that
force a full BTreeMap equality scan on every lookup, which is O(map_size) for
a BTreeMap<String, String>.
The 20× speedup is not “Rust is fast.” It is: zero GC, one allocation per history instead of 540 million, and a cache that does O(1) lookups instead of O(n) equality scans. The algorithmic work is identical on both sides.
Conclusion
This project started as a test harness detour on the way to a Raft implementation. It turned into a useful lesson in several things at once: what linearizability actually means and why it is the right condition for distributed systems testing; how backtracking search with memoization and clever data structures can turn an exponential problem into something tractable in practice; and how Rust’s ownership model makes the performance story here particularly clean — the skip-list’s O(1) in-place mutation is safe without a GC because the borrow checker enforces the invariants at compile time.
The code is at github.com/erwin-kok/porcupine-rs.